Setting up a writing pitch tracking system
AI Disclosure: I used Chat-GPT help for parts of the database design and SQL boilerplate.
I’m trying to get into writing more science journalism. While I’ve done so in the past, mostly with others and as a PhD student, I believe it could be fun to get into it now, specially now that I’m jobless and trying to find stimulating jobs.
Writing is not as much a problem, I think: it seems to me it’s just a matter of practice. Mostly, I’m concerned with organization. I need clutches to keep track of deadlines, tasks and information in general, so I decided I’d set up a postgres database to do so. I wanted the database to include:
- Editor information
- Magazine data
- Pitch-to-magazine related data
- Payment, payrates, how much a venue took to pay, etc
After a while working as a freelance, it could become a unique resource of freelance business information. It does involve some technical knowledge, but I would say not that much for someone with some basic linux skills. It also allows some basic analytics: things like what kind of pitches worked better, where, which places reject or accept more things and how well they pay.
Why not use CSVs, you madman?
Well, I kind of wanted to design a database from scratch. It was a fun procrastination morning exercise, and who knows, it might be useful in the future for others. CSVs also are a bit of a pain, to be honest, specially when you have several interrelated fields.
Database design
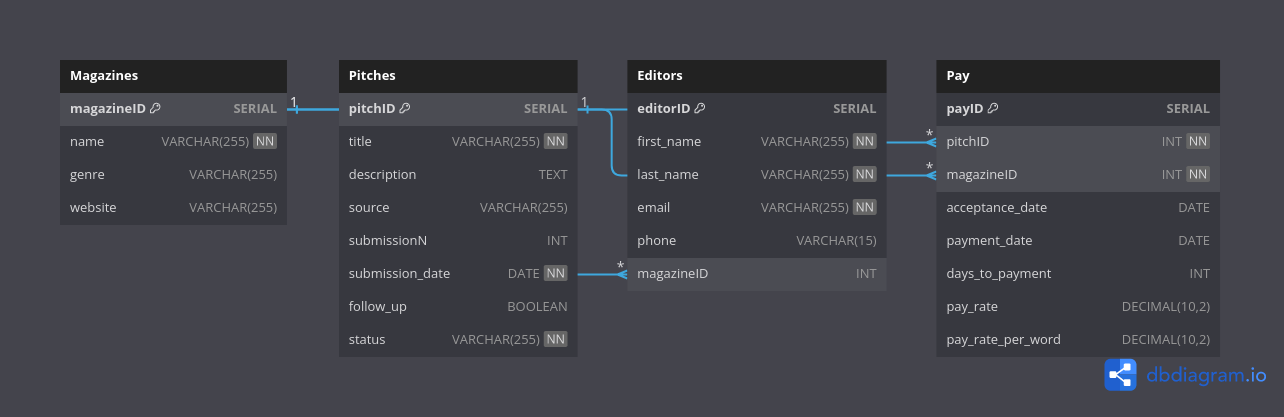
More or less, I was thinking in something like the following tables:
Pitches:
pitchID(Primary Key)titledescription(not as much the topic, but the kind of text: feature, news, post, etc)submissionN(in case a pitch is submitted several times, say, because it was rejected)submission_datefollowup(a boolean, asking if you have followed up to an anaswered pitch)status(e.g., Submitted, Accepted, Rejected)
Note: The actual pitch structure is just a json in a folder consisting on the following:
{
"pitchID": 1,
"title": "Example",
"source": "URL to paper, or whatever",
"pitch": "Lorem ipsum...",
"length": "300 words",
"deadline": "2023-10-30",
"full text": "Lorem ipsum...",
"picture": "/pics/1.png"
}
where the name of the json is also the pitchID. I just like the idea of it being an unstructured json, in case I want to add notes to the pitches in additional fields, but I realize it’s totally unnecesary: some of these fields could also be integrated into the postgres Pitches table.
Anyway, it’ll do for the moment.
Magazine keeps track of basic data from magazines. I’m only include here those I’ve already submitted to in the past.
magazineID(Primary Key)namegenrewebsite
Editors: just basic contact info for editors I get to know.
editorID(Primary Key)firstNamelastNameemailphone(just in case)magazineID(Foreign Key)
Pay: to keep track of payments
payID(Primary Key)pitchID(Foreign Key)magazineID(Foreign Key)acceptance_datepayment_datedays_to_payment(basically,payment_date-acceptance_date)pay_ratepay_rate_per_word(pay_ratecould refer to a fixed ammount; this is normalized)
A note on relationships:
- A
Pitchcan be submitted to multipleMagazines(after rejection in one or several outlets, for example), and aMagazinecan receive multiplePitches(though I don’t expect that to happen often!). - An Editor is associated with one Magazine (normally), but an
Magazine can have multiple Editors. Basically, aone-to-many` relationship. - A Pay(ment) is associated with one
Pitch and oneMagazine` (usually!).
After some rough sketching, my database structure looks like this:
Other details
I decided I’d set it up into a Docker, mostly to make it portable. Here’s my absolutely barebones docker compose file:
version: '3.1'
services:
db:
image: postgres
restart: always
environment:
POSTGRES_DB: pitch_db
POSTGRES_USER: user
POSTGRES_PASSWORD: password
volumes:
- db-data:/var/lib/postgresql/data
ports:
- "8080:5432"
volumes:
db-data:
As you can see, absolutely boring stuff with no frills.
And some boilerplate creationg scripts, in case you want to play with this structure and integrate into your workflow. This more or less follows the data diagram I showed above.
-- Create Magazines table
CREATE TABLE Magazines (
magazineID SERIAL PRIMARY KEY,
name VARCHAR(255) NOT NULL,
genre VARCHAR(255),
website VARCHAR(255)
);
-- Create Pitches table
CREATE TABLE Pitches (
PitchID SERIAL PRIMARY KEY,
title VARCHAR(255) NOT NULL,
description TEXT,
source VARCHAR(255),
submissionN INT,
submission_date DATE NOT NULL,
follow_up BOOLEAN,
status VARCHAR(255) NOT NULL
);
-- Create Editors table
CREATE TABLE Editors (
editorID SERIAL PRIMARY KEY,
first_name VARCHAR(255) NOT NULL,
last_name VARCHAR(255) NOT NULL,
email VARCHAR(255) UNIQUE NOT NULL,
phone VARCHAR(15), -- not even sure I'll use this field ever, but who knows
magazineID INT
);
-- Add foreign key constraint on magazineID in Editors table
-- ie: editors are linked to magazines
ALTER TABLE Editors
ADD FOREIGN KEY (magazineID) REFERENCES Magazines(MagazineID);
-- Create Pay table
CREATE TABLE Pay (
payID SERIAL PRIMARY KEY,
pitchID INT NOT NULL,
magazineID INT NOT NULL,
acceptance_date DATE,
payment_date DATE,
days_to_payment INT,
pay_rate DECIMAL(10,2),
pay_rate_per_word DECIMAL(10,2)
);
-- Add foreign key constraints on pitchID and magazineID in Pay table
ALTER TABLE Pay
ADD FOREIGN KEY (pitchID) REFERENCES Pitches(PitchID),
ADD FOREIGN KEY (magazineID) REFERENCES Magazines(MagazineID);
And some sample data, for this very same post, just to see something in those tables:
-- Sample record for Magazines table
INSERT INTO Magazines (name, genre, website)
VALUES ('My website', 'All about me', 'http://andirko.eu');
-- Sample record for Pitches table
INSERT INTO Pitches (title, description, source, submissionN, submission_date, follow_up, status)
VALUES ('Setting up this database', 'A database for keeping up with pitches', 'Personal Blog', 1, '2023-10-23', false, 'Accepted');
-- Sample record for Pitches table
INSERT INTO Editors (first_name, last_name, email, phone, magazineID)
VALUES ('Alex', 'M. Andirko', 'me@gmail.com', '600 000 000', 1);
-- Sample record for Pitches table
INSERT INTO Pay (pitchID, magazineID, acceptance_date, payment_date, days_to_payment, pay_rate, pay_rate_per_word)
VALUES (1, 1, '2023-10-23', '2023-10-23', 0, 0, 0);
-- I'm not paying myself, obviously
I use DBeaver as a GUI to manage the database, but basically you could use anything.
What next?
I would like to add some data to the Pay table. Basically keeping track of:
- Was the pay rate negociated? (a boolean, obviously)
- Was the pay rate improved by negociating? By how much? (maybe adding fields for old-price / new-price when the previous boolean is
true?).
The data types leave very much room for improvement. It’s ok for maybe a hundred records, but in the long term it might need some improvement. I should
- Revise datatypes.
I’ve been thinking also about how tedious inserting and editing in SQL might become long term here, and whether I can improve usability and kind of wrap this up for non-technical users. So, in that line:
- Write a couple functions to ease the ammount of SQL needed to create and update registries. Maybe a couple python functions with basic CRUD functionality or similar.
- Also: days_to_payment is currently manually calculated, and that’s not nice. It should be automated.
- Maybe check out some
low-code/no-codekind of things that runs in your localhost and is hooked up to your data.
Also: ideally, I would like to automate task management for the following things:
- Sending a mail asking for an update in case a pitch wasn’t paid in a reasonable time
- Idem for non-answered pitches
- Set tasks for developing and sending new pitches
- Set a task including deadline info from pitches
- Real work/hour-tracking would be cool, to actually know how much bang-for-the-buck you get with editing and all.
- I am subscribed to a number of weekly newsletters with pitching opportunities. I would love to parse them into tasks with deadlines and contact details in some automated way (which I kind of do already, but in a very terrible
markdowntable).